想要快速查询磁盘数据,本质就是尽可能高效的在内存中过滤不需要扫描的内容。
存储原理
此处仅讨论MergeTree 系列表引擎
ClickHouse 底层数据通过文件夹分区,当数据到达一定量后,在分区文件夹下,每一个列字段都拥有独立的、以列字段名称命名的.bin数据文件和.mrk索引文件;同时还存在一个主键索引primary.idx(稀疏索引)。
idx、mrk 文件如果是压缩格式,后缀会变为.cidx、.cmrk;同时.mrk 还有多种格式比如:.mrk2、.mrk3
| |
分区
可以通过 PARTITION BY 指定一张表的分区键,通常推荐toYYYYMM(Date)按月分区
此时底层数据会按月存放在文件夹中,方便查询时快速过滤。
分区名称的格式为:202405_minBlock_maxBlock_level,每次数据插入都会生成一个新分区,并在一段时间后,相同分区数据将进行合并,所以插入数据尽量使用批量插入。分区合并完成后,旧分区会标记为不活跃、不会立即删除,在一段时间后才会清理。
| |
注:只有在同一分区(文件夹)内查询,数据才是天然有序的,ReplacingMergeTree去重也只在同一分区内;对于合并前的分区亦是如此,在合并时会才进行排序、去重。
手动触发分区合并
我们可以通过手动执行OPTIMIZE TABLE table_name PARTITION partition_name来进行分区合并
或者直接执行OPTIMIZE TABLE table_name FINAL对整张表进行合并
列式存储
排序
可以通过ORDER BY 指定多个排序字段,最终数据会按照排序字段依次排序存储;列式+排序存储有两个好处:
- 顺序结构能够实现二分查找
- 排序后的数据能够获得更好的压缩率
我们称每一个.bin文件为一个数据片段,数据片段可以以 Wide 或 Compact 格式存储。在 Wide 格式下,每一列都会在文件系统中存储为单独的文件,在 Compact 格式下所有列都存储在一个文件中。Compact 格式可以提高插入量少插入频率频繁时的性能。
数据存储格式由
min_bytes_for_wide_part和min_rows_for_wide_part表引擎参数控制。如果数据片段中的字节数或行数少于相应的设置值,数据片段会以Compact格式存储,否则会以Wide格式存储。
主键和排序字段的关系
主键 ∈ 排序字段
- 如果不指定主键,则排序字段会被隐式指定为主键
- 数据存储是按照排序字段依次顺序存储(可以推导出、主键必须是排序字段的前缀
- 主键索引是常驻内存的
存储格式
每一列数据就是一个单独的bin文件,数据按主键顺序紧密的排列在一起。
在物理层面数据划分为多个压缩块;在逻辑层面又划分为多个颗粒。这个压缩块和颗粒是一对多 or 多对一的关系。
颗粒
颗粒是流进ClickHouse进行数据处理的最小的不可分割数据集,每个颗粒的数据行数由index_granularity参数配置,默认8192。
对于具有自适应索引粒度的表(默认情况下索引粒度是自适应的),某些粒度的大小可以小于 8192 行,具体取决于行数据大小。具体大小由
index_granularity_bytes参数控制。
压缩块
一个压缩块大小为64K ~ 1Mb,如果一个颗粒的数据太小,一个压缩块就会包含多个颗粒内的数据;如果一个颗粒数据又太大,就会拆分一个颗粒的数据。查询时被定位的压缩文件块在读取时被解压到内存中。
索引
主键索引
每个颗粒的第一条数据会被抽出形成主键(稀疏)索引,所以可以得出:主键索引数 == 颗粒数量
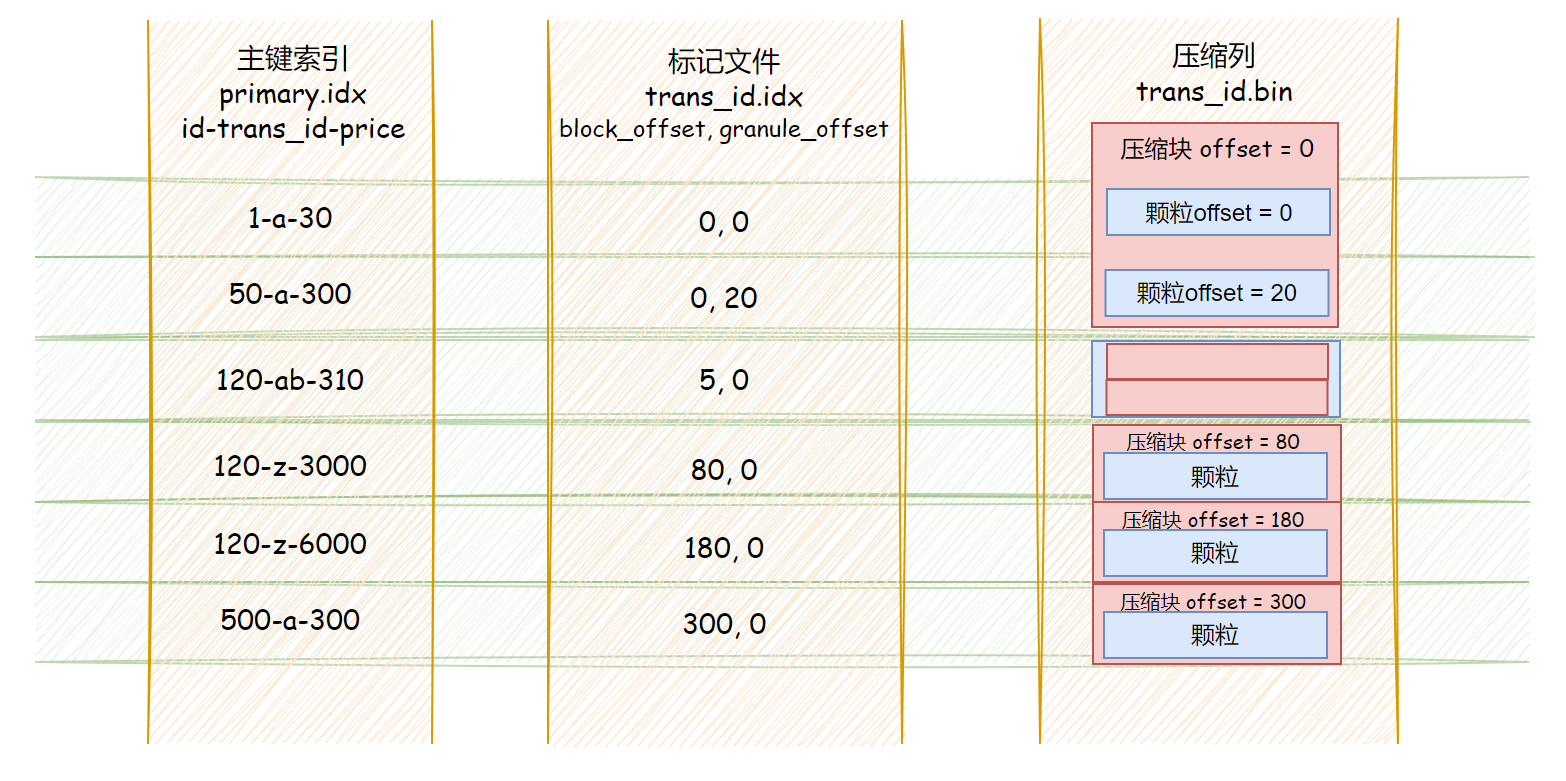
标记文件
标记文件作为主键索引和压缩列数据的桥梁,保存了两个偏移量信息(位置);同时主键索引数 == 标记文件行数
- 第一列标识数据所在压缩块位于整个压缩列(.bin文件)的偏移量
- 第二列标识数据在解压数据块中的偏移量
因为标记文件的两列是定长字段,所以通过主键所在列序号就能找到对应的标记文件。
再通过标记文件列的两个偏移量,就能定位到对应的颗粒
跳数索引
二级索引
总结
为什么需要标记文件?
为什么主索引不直接包含与索引标记相对应的颗粒的物理位置?因为主索引文件需要放入内存中,如不用标记文件,则需要将每列的偏移量都存储在主键索引中,浪费内存资源。
为什么会有压缩块?
- 为什么颗粒和压缩块不一一对应
压缩块设计更多是为了存储和IO优化,而颗粒是为了调整查询效率;两者解耦更灵活
- .bin就是一个文件,为什么内部要分块压缩
因为压缩算法是需要结合数据上下文进行压缩,没办法根据偏移量单独取出一块读取,所以将原始数据先分段后压缩,能够减少每次查询所需读取解压的数据量
多主键优化
本质上是全量复制一份数据,按照新主键的顺序重新生成底层文件系统。有如下三种方法
- 新建一个不同主键的新表:需要双写手动维护,读取时需要手动选择读取的表
- 创建一个物化视图:数据表自动同步,但读取时仍需要手动选择读取的表
- 增加projection:数据表自动同步,读取时自动选取最合适的表
二进制索引文件分析
因为不懂C++,尝试从源码分析有点无从下手,所以直接针对二进制文件,通过猜测+验证找出索引排布规律,故本文只分析部分数字+字符串类型的索引。
| |
现在插入两条数据:
| id | trans_id | product_id | price |
|---|---|---|---|
| 1 | abcdefg | product | 15 |
| 2 | abcdefgh | product | 30 |
| 3 | abcdefghijklmn……opqrstuvwxyz (总长度260) | product | 3000 |
| 4 | b | product | 3000 |
| 5 | c | product | 3100 |
| 6 | d | product | 3400 |
那么索引应该是类似这样的格式:UInt16-String-UInt16
即: 1-abcdefg-15 3-abcdefg...xyz-3000 5-c-3100
primary.idx
接下来通过 hexed 打开primary.idx验证猜想,如下图所示:

- 数字 会按照定义类型,占用固定大小
- 字符串 分为长度和数据两块,其中长度部分会根据数据大小占用一到多个字节
此时肯定会有一个疑问,当String长度大于一个字节能表示的范围(255)时,应该怎么储存?
我给出一个个人猜测的在一定范围适用的公式,假设是两个字节表示长度,两字节转10进制分别为:A、B
则字符串长度为 A + 128 * (B - 1),带入上面第二行数据即为:132 + 128 * (2 - 1) = 260
也可以通过JavaScript 直接计算:parseInt('84', 16) + 128 * (parseInt('02', 16) - 1) = 260
注:这个B的值应该只会在[0, 一个小数]内,这样才能准确截断长度字段与数据字段。有懂哥愿意贴上C++源码层面的分析最好不过了。
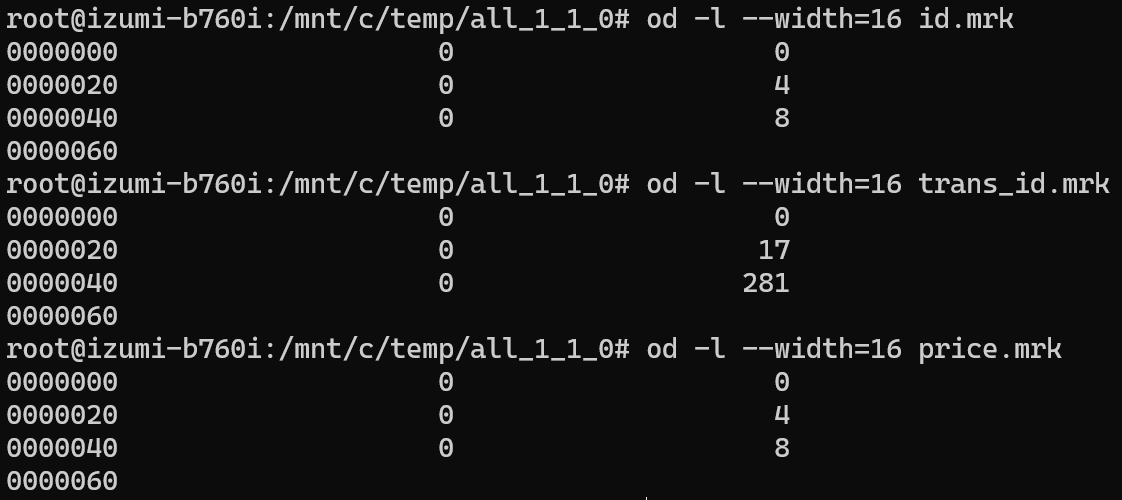
column.mrk
.mrk 是一个两列多行文件,行数和primary.idx 相当且按序一一对应
比如id.mrk 一共三行,代表有三个颗粒;第一列都是0,代表全部属于同一压缩块;第二列是0、4、8正好就对应了解压后的id字段长度。

而trans_id.mrk是不定长的字段,所以第二列分别为0、17、281
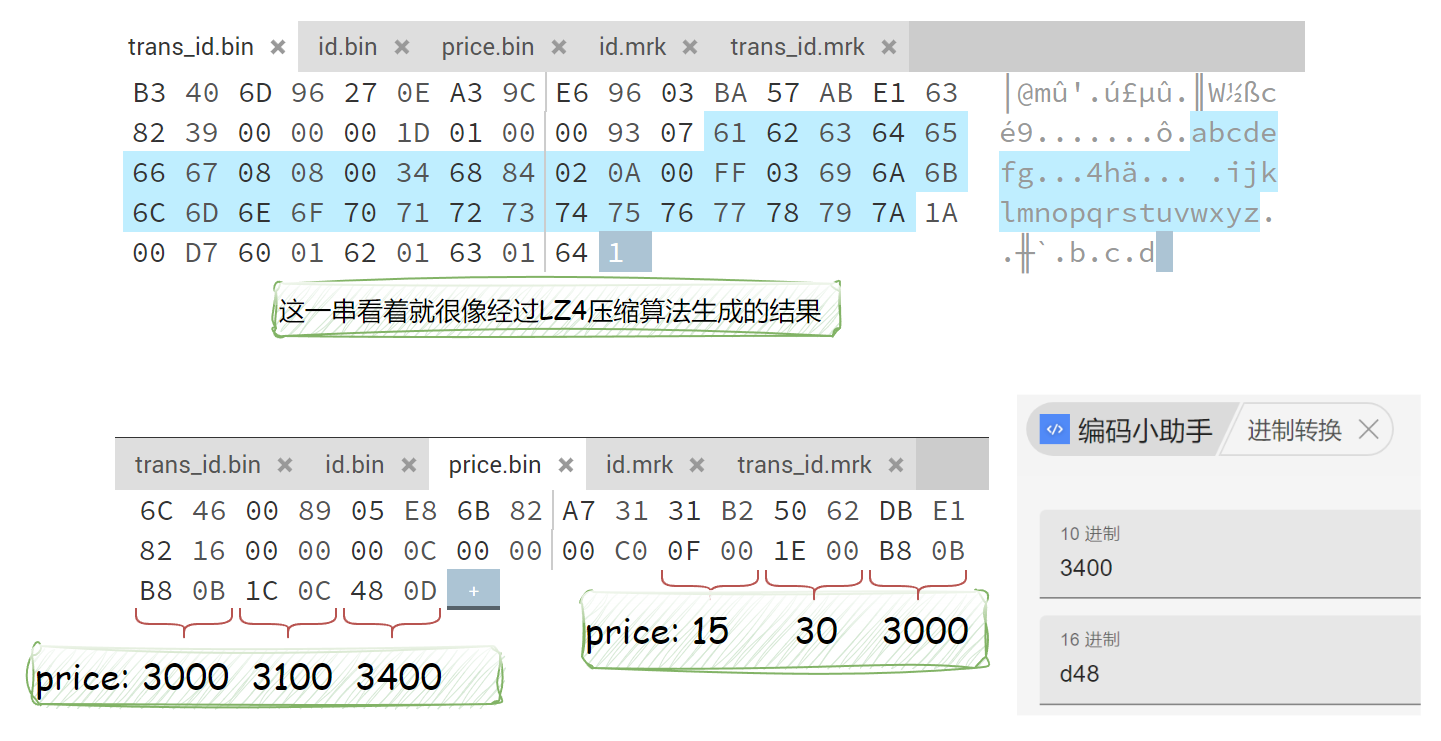
column.bin
.bin文件就是最终数据存储的地方,是一个压缩的数据列,直接打开只能大概窥探一下数据样貌:
每个压缩块由头文件+数据文件组成,头文件包括压缩协议、压缩前后大小信息
向量引擎
可以很好的利用CPU的SIMD指令:单指令流多数据流(英语:Single Instruction Multiple Data)
SIMD(Single instruction, multiple data)单指令多数据,是一种通过单个指令同时进行多个数据运算的方式,通过增加运算单元位宽、计算单元数量数量、寄存器位宽可以同时进行更多数据的运算,普通指令单个周期通常只能支持 2个数据的运算,SIMD指令单个周期可以同时几十个数据的运算。
多线程
ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
因为数据通过分区、多列、颗粒等划分明显,所以很简单的利用多线程进行读取;单个查询就能消耗相当多的CPU资源,当然这带来的缺陷就是QPS较低。
分布式、多副本
可以通过 zookeeper 进行数据协调,将数据存储在多机器上。